2020 年中時,一個叫做 Edge Impulse 的新創公司推出了個線上的 TinyML 平台,讓使用者能更容易地訓練神經網路模型、並把它們佈署到嵌入式硬體上。Edge Impulse 和 Arduino、Tensorflow、Arm 以及 Nordic Semiconductor、STMicroelectronics 等晶片廠都有合作,並使用自己開發的 Edge Optimized Neural (EON) 技術來進一步縮小神經網路模型的大小跟記憶體用量。
我之前寫過一篇介紹 EloquentTinyML 這個函式庫的文,它可以用比較簡單的方式將 Tensorflow Lite 神經網路模型佈署到開發板上;事實上我後來甚至嘗試實作了一個簡易的語音辨識專案。然而,這和 Edge Impulse 提供的介面及功能性相比實在陽春太多,而且後來慢慢理解到我用的模型結構其實也不適合語音辨識。但,當時我缺乏足夠的認知,實在也無力去設計一個合適的深度學習模型。
當我聽說人們可以把現成資料整合到 Edge Impulse 網站上時,就感覺應該來玩玩看。最後做出來的成果也確實令我訝異:模型的單字語音辨識率竟能達 90% 以上,而且在裝置上運作良好。
TinyML,或 embedded machine learning,就是在嵌入式裝置這種運算速度跟記憶體都很有限、但耗能也低的裝置上運作的機器學習/人工智慧技術,近來在國外越來越受矚目。因為若能在終端裝置上跑 AI,那麼你就不再需要仰賴昂貴的中央運算設備,而是能將 AI 推向監測現場或使用者,包括用在穿戴式醫療裝置上。(去年 Edge Impulse 就透過合作的創客社群 Hackster.io 辦了一個用 TinyML 來保護瀕臨絕種大象的比賽。)
只是,基於軟硬體的特殊需求,TinyML 要在一般創客圈普及也不是那麼容易,況且目前任何 TinyML 支援的硬體種類都是有限的。所以 Edge Impulse 也許正好代表了 TinyML 的一種未來趨勢:以類似 AutoML(自動化機器學習)那樣將模型的訓練及佈署包裝成圖形化平台,並針對合作對象的硬體提供服務。例如,台灣的奇景光電前陣子就宣布和他們合作,而該公司的 Himax WE-I Plus 開發板也已經列在上頭。
Edge Impulse 平台本身是完全免費的,一般人使用上並沒有什麼限制;它的營利管道就是靠著與廠商的合作。

在這一篇,我將展示如何使用 Arduino Nano 33 BLE Sense 來佈署一個 Tensorflow Lite 模型。這開發板是 Edge Impulse 正式支援的產品之一,處理器時脈為 64 MHz,記憶體 256 KB,跟其他專門針對 TinyML 而開發的產品相比比較像業餘性質;但你將發現它仍然有能力進行基本的語音辨識功能。(國內有廠商有賣,我就不打廣告了 — — 注意別買錯型號,後面有 Sense 的才有裝麥克風。)

Edge Impulse 支援的開發板列表請見此。事實上該平台也支援樹莓派 4、NVIDIA Jetson Nano、手機和 WebAssembly 作為佈署目標。
而這一切最神奇之處,就是你可以在完全不寫程式的前提下完成模型訓練及佈署。當然若想要的話,我們還是可以修改 Edge Impulse 最終提供給我們的程式,好讓開發板在辨識時能做些事情。
1. 建立一個 Edge Impulse 專案
首先,當然是到 Edge Impulse 網站申請一個帳號:
注意:為了截圖方便,我把視窗縮到螢幕的半邊展示。這會和全螢幕下看到的版面稍有不同。
登入後新建一個專案,在此我們就稱之為 my_sound_detection:
進入專案主控台後,你會看到一個精靈畫面,詢問你想要使用哪類型的資料:
既然是語音辨識,就點選 Audio。下個畫面會告訴你,你有兩種方式可以上傳訓練用的聲音檔案:透過開發板的麥克風,或是從電腦上傳 WAV 檔。
2. 上傳語音資料集
使用現成資料
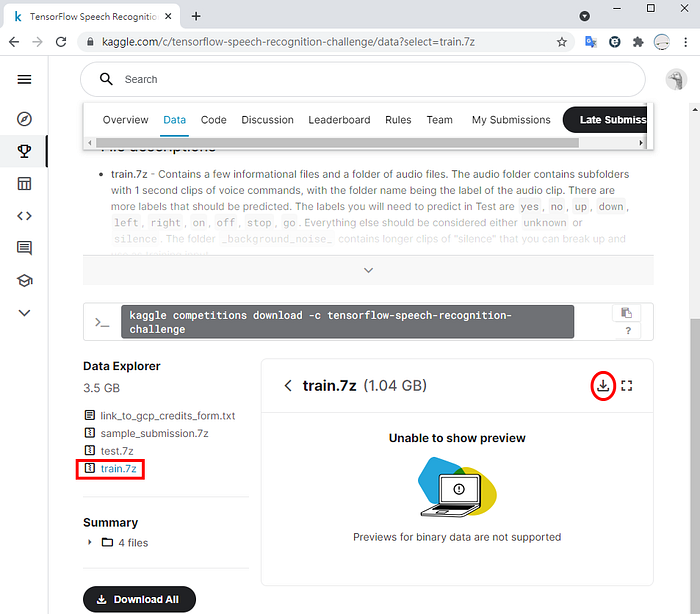
下面我們會來看這兩種做法,首先是用已經存在的語音資料集 Google’s Speech Commands。這個資料集包含多個單字,每筆錄音只有 1 秒長,由數千人錄製而成。你可以在 Kaggle 網站上下載其訓練集(需先註冊免費帳號):
把 train.7z 解壓縮後,可以在裡面的 train\audio 目錄下看到不同單字的錄音檔資料夾:
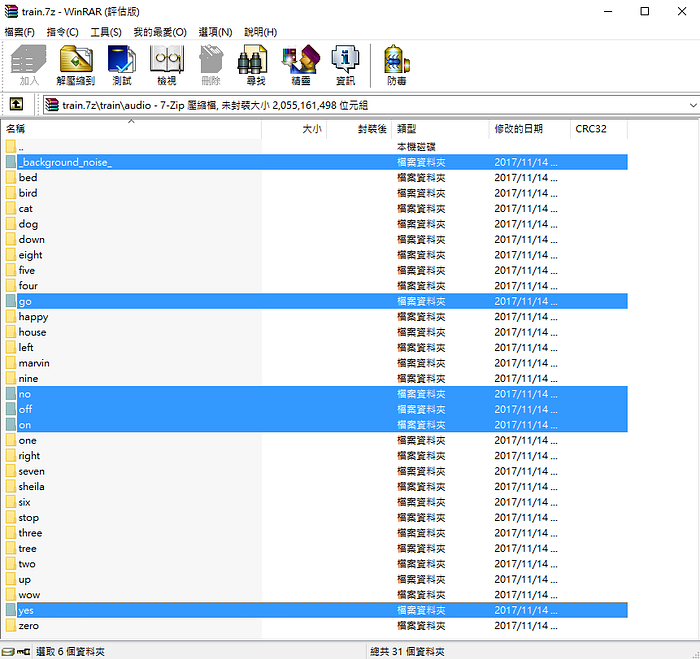
這裡我們只選取其中五個詞:yes、no、on、off 和 go,此外則是一些背景噪音。把它們解壓縮到電腦裡。我其實並不清楚你究竟可以辨識到多少詞、但模型仍然能塞進開發板裡。有興趣的人也許可以試試看增加數量吧。
現在回到 Edge Impulse,點左邊選單的 Data acquisition:
點「Lets collect some data」:
在跳出來的畫面選「Go to the uploader」:
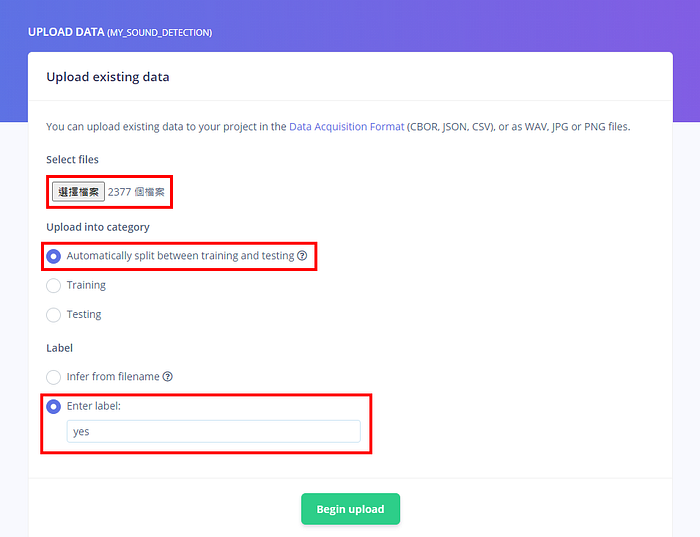
現在我們要上傳剛才下載的語音檔,選擇自動分成訓練和測試集而且給它們指定標籤(label,模型用來判定的分類名稱)。你可以看到 Edge Impulse 的上傳器也支援 JSON、CSV、圖片等資料來源。
例如,我先選擇 train\audio\yes 目錄底下的 2377 個檔案,並指定標籤為「yes」,就可以按「Begin upload」來上傳:
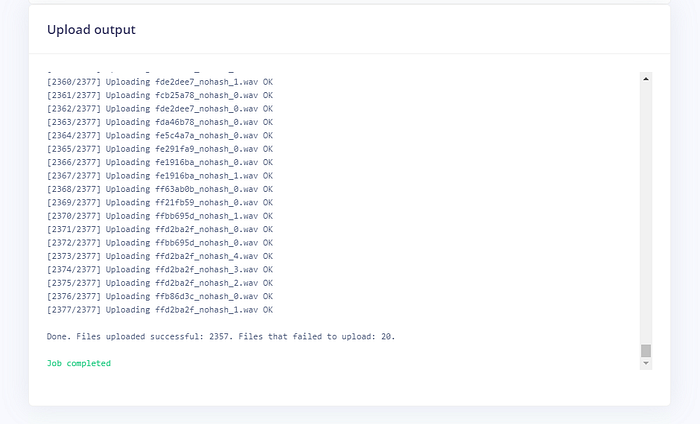
有些檔案因為其雜湊值相同而被認為是重複資料,不過可以看到最終仍上傳了 2357 筆錄音:
重複以上過程,上傳代表 no、on、off、go 以及 background(背景噪音)的檔案。
不過,由於 background 只有 6 個檔案,所以我把它們全部設為 Training(訓練集)。而且稍後我把它刪到只剩 4 個 — — 見下小節說明。
最後回到 Data acquisition 畫面,你可以在這裡管理資料。
從開發板錄製和上傳語音
另一個方式是從我們的 Arduino Nano 33 BLE Sense 的麥克風現場錄音和上傳聲音檔。我們需要在開發板上安裝 Edge Impulse 提供的特殊韌體,以便讓它和網站溝通。
正常情況下,你也需要安裝 Edge Impulse CLI 工具來「連線」,不過現在 Edge Impulse 網站支援使用 Google Chrome 瀏覽器的 WebUSB 功能來直接連接裝置。這也是下面我們會使用的做法。
首先下載 Arduino Nano 33 BLE Sense 韌體。在壓縮檔中,會有個 arduino-nano-33-ble-sense.ino.bin 韌體檔以及針對 Windows、macOS 和 Linux 的檔案。以 Windows 來說,執行 flash_windows.bat 批次檔就能上傳韌體到板子。
但這個批次檔需要一個工具叫做 Arduino CLI。點進連結和尋找符合你平台的版本:
以 Windows 來說,只要把下載的壓縮檔當中的 arduino-cli.exe 跟前面的韌體檔放在同一目錄即可,不須任何安裝手續。
現在用 USB 線連接 Arduino Nano 33 BLE Sense 到電腦,並執行 flash_windows.bat(Windows 防火牆可能會嘗試攔截它,故選擇繼續執行)。你會看到燒錄畫面跳出來:
Finding Arduino Mbed core...
arduino:mbed_nano 2.2.0 2.2.0 Arduino Mbed OS Nano Boards
arduino:mbed_rp2040 2.2.0 2.2.0 Arduino Mbed OS RP2040 Boards
Finding Arduino Mbed core OK
Finding Arduino Nano 33 BLE...
Finding Arduino Nano 33 BLE OK at COM31
arduino:mbed_nano 2.2.0 2.2.0 Arduino Mbed OS Nano Boards
Device : nRF52840-QIAA
Version : Arduino Bootloader (SAM-BA extended) 2.0 [Arduino:IKXYZ]
Address : 0x0
Pages : 256
Page Size : 4096 bytes
Total Size : 1024KB
Planes : 1
Lock Regions : 0
Locked : none
Security : false
Erase flashDone in 0.004 seconds
Write 525440 bytes to flash (129 pages)
[==============================] 100% (129/129 pages)
Done in 22.655 seconds
Flashed your Arduino Nano 33 BLE development board
To set up your development with Edge Impulse, run 'edge-impulse-daemon'
To run your impulse on your development board, run 'edge-impulse-run-impulse'
請按任意鍵繼續 . . .
現在回到 Edge Impulse 的 Data acquisition 畫面,點選「Connect using WebUSB」:
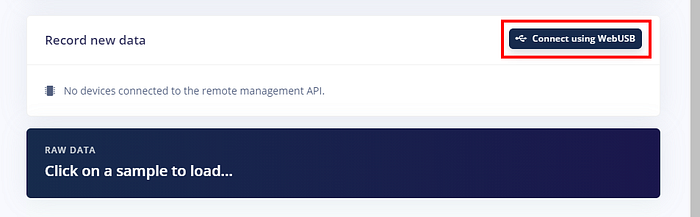
你應該會在 Chrome 的 WebUSB 清單上看到你的開發板,選擇後點「連線」:
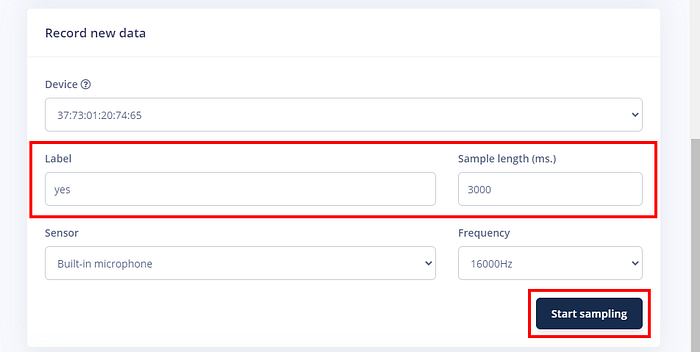
連線的裝置一出現在網站上,就可以開始錄音了。你可以設定錄音的標籤(比如「yes」)並設定取樣的時間長度(這裡我們設為 3000 毫秒,以免自己反應不及):
等待開始錄製的提示出現,然後對著麥克風說話(我會避免直接對著麥克風說,而是把它貼近嘴的側面,以免呼氣造成爆音)。
錄音上傳後,你可以檢視和聆聽錄音內容,並更改其分類標籤、加以裁切或刪除:

在此我就意思意思一下,對要辨識的五個詞各自錄了一段音,並把長度裁切為 1 秒。
此外,在聽過分類為 background 的背景噪音檔案後,我決定把 pink noise 和 white noise 刪掉,因為太吵了,不符我的環境條件(房間裡)。這使得背景噪音只剩 4 個檔案;但由於它們很長,下面取樣後仍然能產出不少資料。
3. 抽取資料特徵
建立 impulse
網站上所謂的 impulse,其實就是一個流程,我們得告訴 Edge Impulse 如何產生特徵(features)資料,以及要用什麼方式來訓練模型。
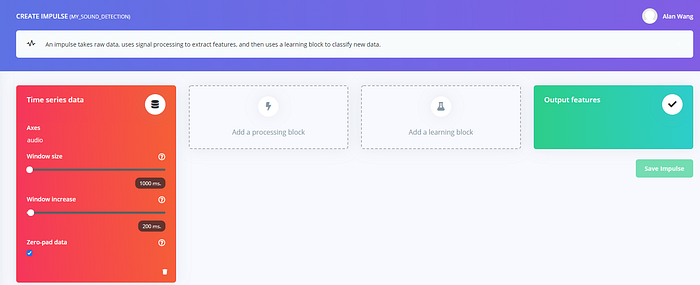
首先是滑動窗格(sliding window)的大小,因為有些語音檔可能很長,但裡面只有一小段會包含我們想辨識的資料…因此做法是每次截取一小段,然後逐漸移動這個「窗口」來掃描不同段落。同樣的原理其實也被應用在視覺辨識中。

由於所有的語音檔都是 1 秒,因此這裡 windows size 設為 1000 毫秒。我們也把窗格移動距離設為 250 毫秒,並且對長度不足的資料補 0(勾選「Zero-pad data」)。前面提到背景噪音的錄音很長,因此藉由移動的窗格就能產生大量的樣本,好讓裝置能在我們不說話時將之辨識為背景噪音。
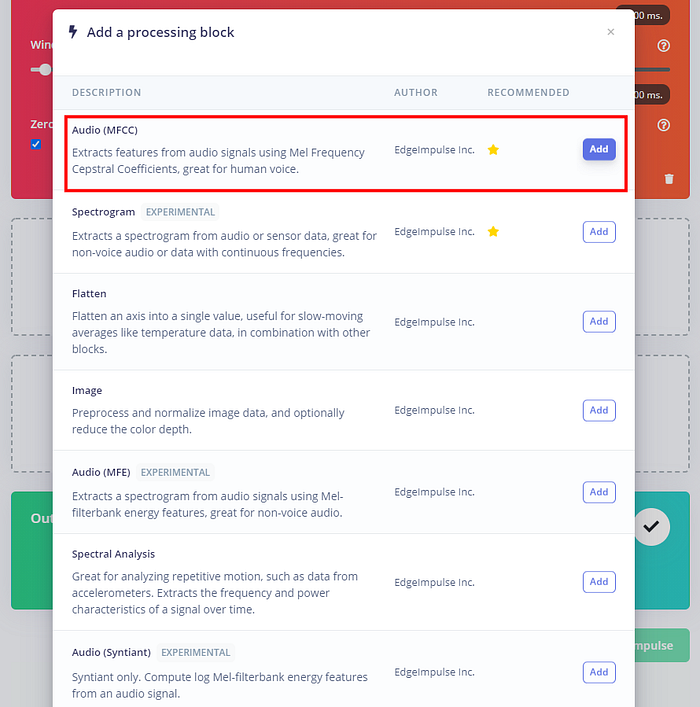
接著是在 processing block 選一個處理資料的方式,Edge Impulse 推薦我們使用適合處理人聲的梅爾頻率倒譜係數(MFCC):
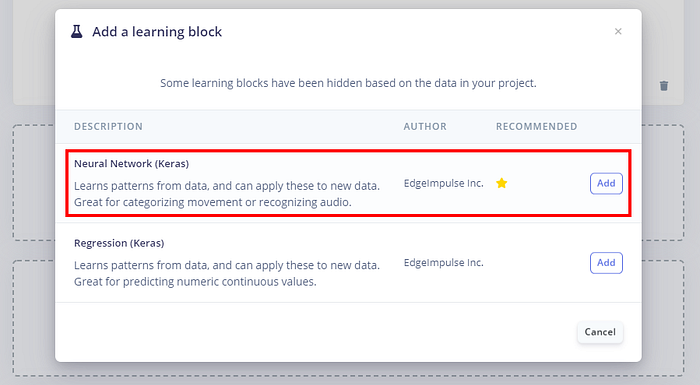
第三是替 learning block 選擇要使用的模型,有神經網路和迴歸,可以看到都是出自 Tensorflow/Keras。這裡自然就選神經網路。
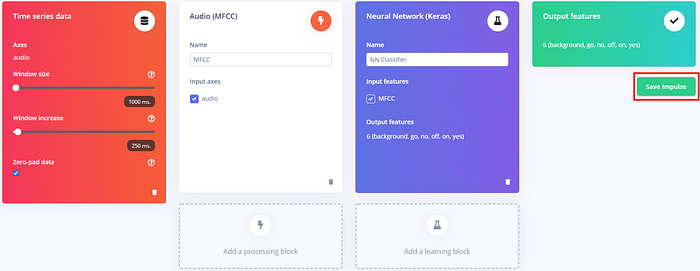
最後確定 processing block 和 learning block 都有勾選來源資料,然後按下「Save impulse」來儲存它:
進行特徵擷取
現在點選左邊選單 Create impulse 底下的 MFCC,你可以檢視上傳的資料的特徵分析結果。
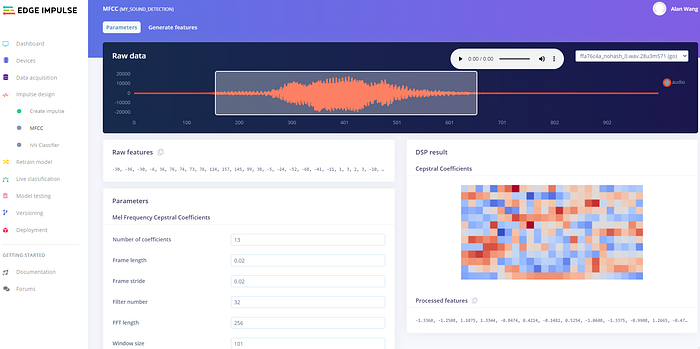
這裡我們不做更動,直接按畫面底端的「Save parameters」。這會帶你跳到下一個畫面來準備產生特徵資料:

按「Generate features」來開始產生特徵資料,等待作業結束(有可能會失敗和得重來)。完成後你會看到 Edge Impulse 產生了三維的特徵分佈圖:
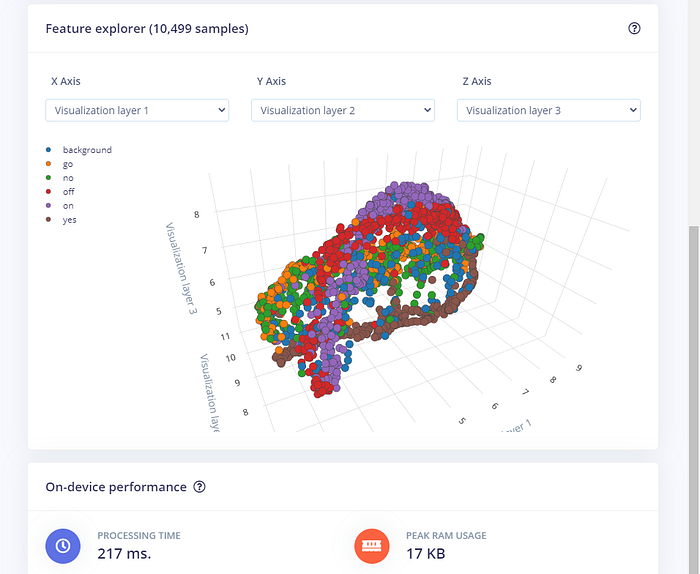
4. 訓練神經網路模型
特徵資料產生好之後,點左邊選單的 NN Classifier,這個畫面能讓你設定神經網路的一些參數,包括訓練次數、學習速率、模型的結構等等。
點左上角來給你的模型一個版本號(不強制):
在這個畫面底下是神經網路的內容,學過 Tensorflow/Keras 的人應該會覺得眼熟。模型內有兩個隱藏層,分別有 8 和 16 個神經元,但這樣有點少、訓練出的模型效果會較差,所以在此我把兩層都改成 64 個神經元:
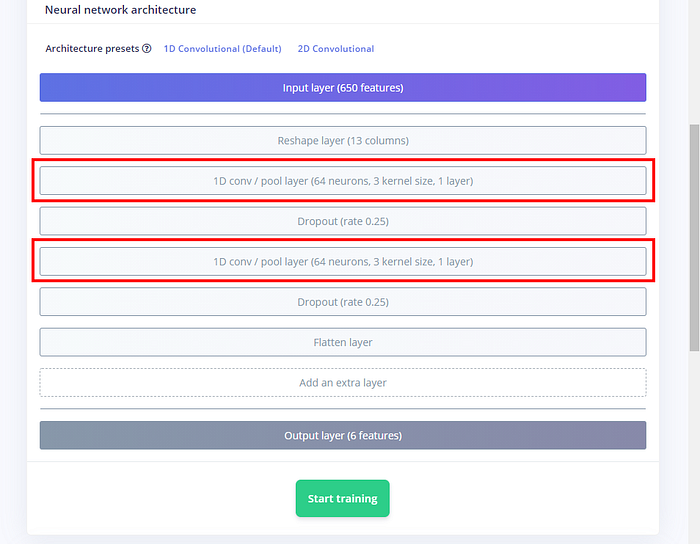
要如何找到最適當的神經網路模型,這就是較進階的議題了,總之若訓練成效不佳,可以試試增加神經元的數量。
補:不過你也可以不必手動設定模型。參閱本文結尾的 EON Tuner,了解如何以自動化方式尋找可能的最佳模型。
無論如何,按下畫面底端的「Start training」開始訓練,然後等待模型訓練完畢(要花點時間,且同樣有可能會半途掛掉)。
等它完成後,你就能看到模型的訓練成效(在此預測準確率達 93.1%)、對個別標籤的預測能力,最下面也有模型的存取速度跟記憶體用量:

預設上 Edge Impulse 會將模型轉成 Tensorflow Lite 並會做量化(quantization),也就是將值轉成 in8 整數來處理,藉由犧牲少許精確度換取更快的速度,且占的空間更小。
5. 測試模型
在把模型佈署到裝置上之前,現在我們可以先來測試一下。點左邊選單的 Live classification,然後照前面講過的方式連接 Arduino Nano 33 BLE,錄音長度同樣設為 3000 毫秒。
Edge Impulse 上傳錄音後,會顯示它的預測結果。下面是我對麥克風說「yes」的結果;由於錄音時間比訓練資料長,我們先把原始聲音資料視窗中的窗格拉到說話的所在位置:
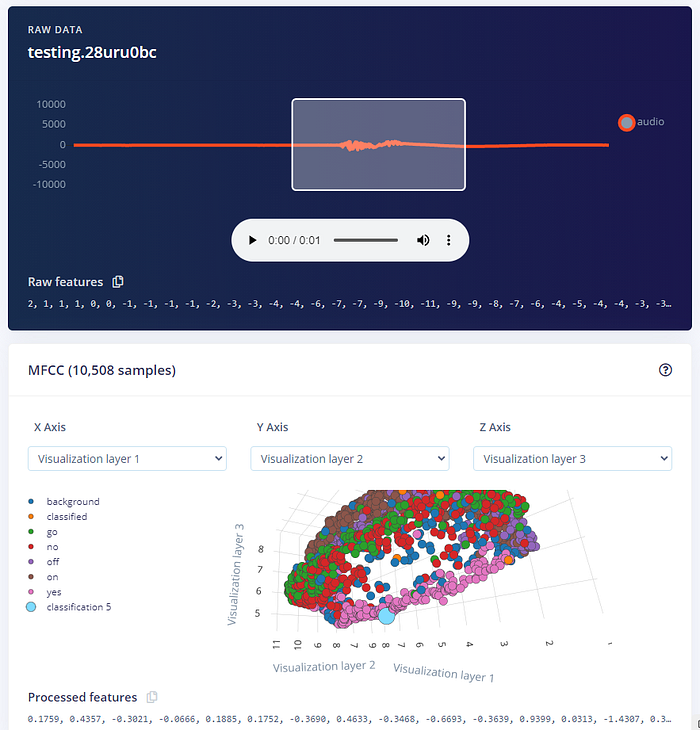
注意你在此的錄音會被上傳為測試資料。你可以回到 Data acquisition 畫面,點上面的「Test data」來編輯、裁切或刪除它。
在畫面的另一邊,則能看到神經網路模型對於不同位置窗格的預測結果。可見當窗格大致位於說話位置時,判定為「yes」的機率達到 98%~100%:
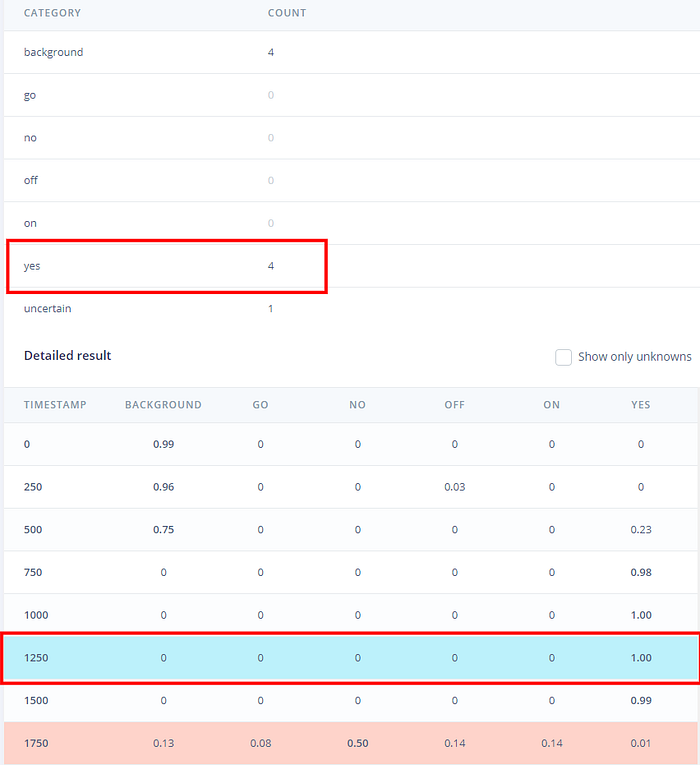
附帶一提,你也可以點選單的 Model testing 來看看模型對測試集的預測效果。以本篇的模型為例,我得到 90.69% 的預測準確率。
6. 匯出模型
現在是這一切的重頭戲:把這個神經網路模型搬到 Arduino Nano 33 BLE Sense 上,使它成為真真正正的 TinyML。
這有幾種可行的方式,在此我用的是把它下載成 Arduino 函式庫,使你可以在 Arduino IDE 匯入它。這意味著你之後可以進一步修改它,讓開發板在聽到指令後做某些事。
點選選單最底下的 Deployment,然後點「Arduino library」:
如果選下面的 Arduino Nano 33 BLE Sense,則會下載一個韌體檔,其燒錄方式跟前面的韌體一樣,但這就必須用 Edge Impulse CLI 工具來執行 — — 一來你必須先安裝 Node.js 跟 Python,二來這韌體除了輸出預測結果文字以外沒有半點用途。
還是想玩玩看 Edge Impulse CLI 的人,可參閱官方文件。
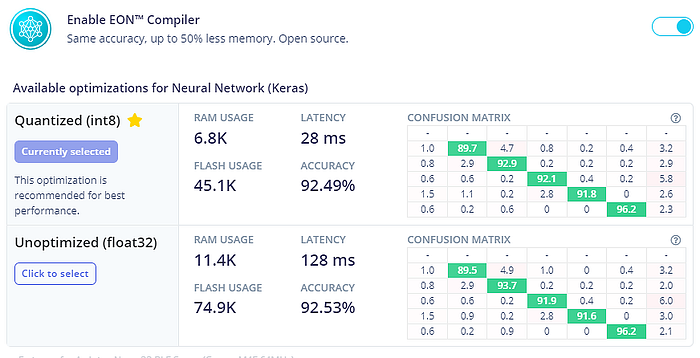
選到畫面最底下,先點「Analysis optimization」,來看看模型有無量化的差別:
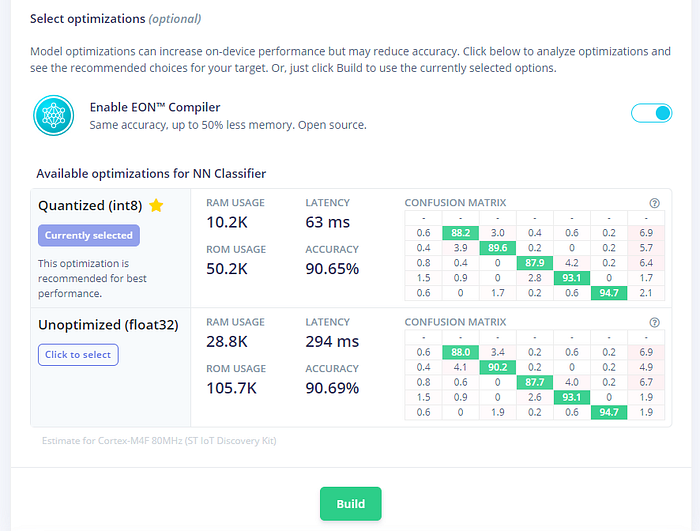
可見量化後預測效力幾乎沒有下降,模型卻變得更小、更快和更輕了。這樣很好,這代表你之後可以善用板子上更多的記憶體給其他功能使用。
一切就緒,按下面的「Build」來開始編譯。這會下載一個 .zip 檔,但先別急著把它解壓縮。
7. 在 Arduino IDE 匯入並上傳模型
下載 Arduino IDE,安裝好和啟動,打開工具 → 開發板 → 開發板管理員,找到並安裝「Arduino Mbed OS Nano Boards」:
選擇正確的開發板以及序列埠:
接著點草稿碼 → 匯入程式庫 → 加入 .zip 程式庫,選取你剛才下載的那個壓縮檔(以我為例是 ei-my_sound_detection-arduino-1.0.1.zip)。Arduino IDE 會告訴你函式庫已加入。這時你即可從檔案 → 範例來找到你的專案:
_continuous 結尾表示程式會連續不斷偵測語音。上面另一個麥克風範例雖然也會連續,但兩次之間會有停頓。
載入程式碼後就可以上傳了:
編譯和上傳要花不少時間,所以得稍等一會兒:
草稿碼使用了 308520 bytes (31%) 的程式儲存空間。上限為 983040 bytes。
全域變數使用了 48200 bytes (18%) 的動態記憶體,剩餘 213944 bytes 給區域變數。上限為 262144 bytes 。
Device : nRF52840-QIAA
Version : Arduino Bootloader (SAM-BA extended) 2.0 [Arduino:IKXYZ]
Address : 0x0
Pages : 256
Page Size : 4096 bytes
Total Size : 1024KB
Planes : 1
Lock Regions : 0
Locked : none
Security : false
Erase flashDone in 0.000 seconds
Write 309280 bytes to flash (76 pages)
[==============================] 100% (76/76 pages)
Done in 12.907 seconds
一個可以辨識六種結果(五個詞加背景噪音)的神經網路模型,實際上只用了 47 KB 記憶體,是不是很厲害?
若要更新你的模型,打開文件\Arduino\libraries 然後刪掉函式庫 — — 以我為例是 my_sound_detection_inferencing — — 然後重啟 Arduino IDE 和再新增一次。
再次確保板子的序列埠有正確設定(上傳程式後常會跳掉,因為 Nano 33 BLE 的燒錄模式會在另一個序列埠號),打開工具 → 序列埠監控視窗,並選擇右下角的 baud rate 為 115200。你會看到程式輸出每一個結果的預測值,以及預測所花的時間:
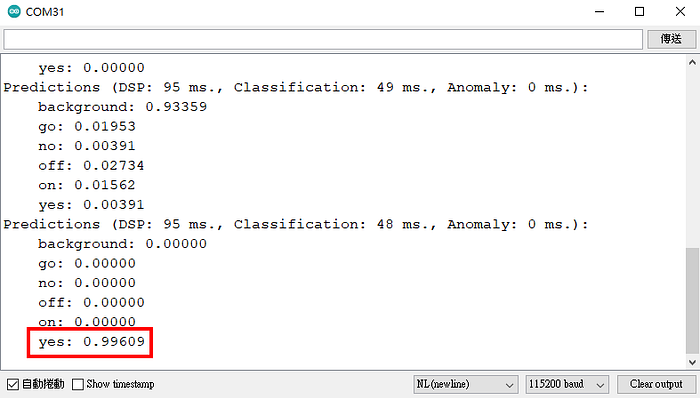
只要判斷每次取樣後哪個字的預測機率最大,它就是最終的預測結果。
在上圖中,我不說話時背景噪音的預測值為 93.3%,而當我對著麥克風說「yes」時,該分類就跳到 99.6%。事實上就我測試,五個字的反應都相當好,判定機率都落在 85%~95% 以上,同時其他字的判定機率則趨近於 0,除非是你說話時剛好跨在兩次預測的時間中間。
8. 結語
其實總歸來說,Edge Impulse 平台所做的過程跟我之前自己寫程式仍是差不多的,且多少還是需要自行調校模型(希望將來它可以跟 AutoML 結合)。但這個圖形化的介面允許你更方便地管理資料,而且也能替你應付怎麼從感測器(比如麥克風)收集資料。在我自己做的專案中,一個問題就是麥克風的收音效果不佳,而且當時為了簡化,我測量的是音量變化而不是頻率變化。在聲音資料的處理上,Edge Impulse 實在是方便太多了,實測的效果也比想像中好很多。
TinyML 仍是個剛起步的領域,但其實已經可以看到這個市場開始進入激烈競爭,越來越多高端微控制器紛紛問世。Arduino Nano 33 BLE Sense 以業餘創客開發板來說並不便宜,但和其他瞄準 TinyML 的裝置來說卻算平價了;拿 Edge Impulse 支援的另一款板子,野心勃勃的 Arduino Portenta H7 為例,就要價台幣近四千,甚至比 NVIDIA Jetson Nano 還貴。至於什麼時候 TinyML 能夠下放到真正平價的嵌入式硬體,以及是否能完全平民化、能夠應用在多廣泛的地方,仍是有待觀察的。
我寫完這篇時,Edge Impulse 尚未正式支援新出的 Arduino Nano RP2040 Connect,但很快的應該就會了。這個板子處理器更快、有麥克風跟 ESP32 模組,所以可以拿來實作 AIoT 應用 — — 讓裝置在現場做好辨識後透過網路上傳結果。說不定到時甚至會有人做出用低階攝影機模組做影像辨識的應用哩。
補:後來試了一下,我下載的 Arduino library 是可以上傳到 Nano RP2040 的,只是跑模型時常會發生記憶體不足現象。還不知道若改用較小的模型是否就能成功。
補記:使用 EON Tuner 自動尋找最佳模型
在寫完這篇的一陣子後,Edge Impulse 加入了個能讓你用他們的 EON Tuner 來尋找最佳模型的功能,等於是加入了 AutoML 自動化建模。你可以選擇編譯目標(要跑模型的裝置),然後讓它去試驗十幾種不同的神經網路。以我為例,等大約一小時後,就可以根據訓練結果挑選你想要的成果。
不過官方也說這是在發展中的功能,而有趣的是,我得到的最佳模型在測試集準確度上比上面的結果低 3%。但我也還沒仔細看相關設定,所以這部分大概還有待進一步研究。

※補記二:
後來發現只要把 time per inference(每次做預測的時間間隔?)調高一點就好了。預設是 100 毫秒,我改成 300,這對人類來說差別不會太大。前面模型在未量化之前,latency 其實也有將近 300 ms。

然後來重新訓練:


可見最佳模型對驗證集的預測表現有顯著的提高,比我一開始手動設定的模型更好(從 93% → 96%),畫面上也會列出 EON Tuner 找到的模型(但看起來每層神經元都是以 16 為倍數)。
選擇表現最好的模型(預設是以對驗證集的準確率排序),然後來看它對測試集的表現(點左邊選單的 Model testing):
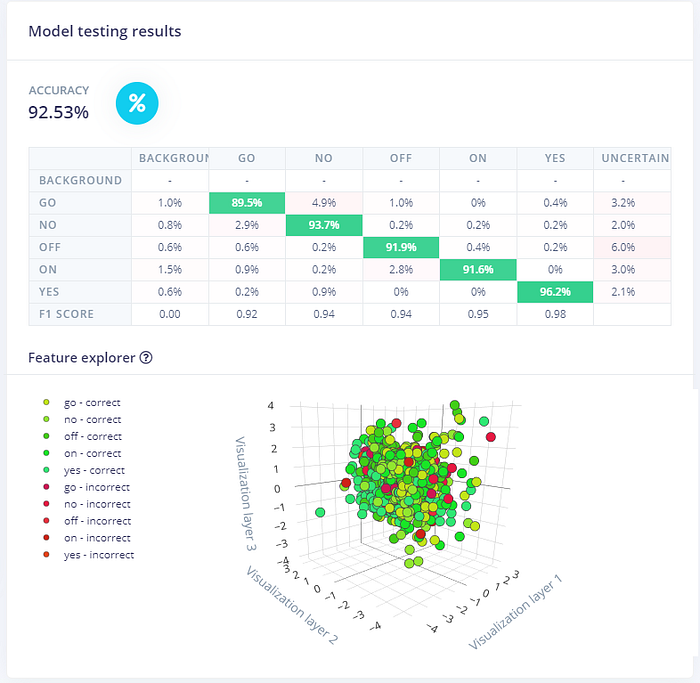
從 90.5% 提高到 92.5%,也是不錯。
目前在 Deployment 頁面點 Arduino library 後,該頁底下也會自動顯示最佳化後的比較: