前陣子筆者買了本書 TinyML,這本書是講如何在(特定的,咳咳)開發板上佈署 Tensorflow Lite 神經網路模型。我個人雖然對 Tensorflow 幾乎一竅不通,但對於如何在微控制器或開發板應用它,倒是相當有興趣。
(其實廣義來說,TinyML 可以泛指將機器學習用在微控制器的領域。不過,這邊主要以 Tensorflow Lite 為主。)
不過讀一讀就發現就發現,佈署模型的過程似乎相當繁雜,且並不是在 Windows 環境下進行,對筆者這樣的初學者來說實在不友善。此外,若打開 Arduino IDE 內的 Tensorflow 範例,一口氣就跳出 8 個檔案,程式碼也密密麻麻的,看了真教人心驚驚。
這就好像有人介紹給你一個很酷的東西,結果講到重要的實作細節,你就卡住難以前進了,有苦難言。想要玩 TinyML,真的得這麼痛苦嗎?
結果,當我在 Arduino IDE 的函式庫裡亂搜尋時,意外找到一個叫做 EloquentTinyML 的函示庫。一看它的範例不得了,就只有一個主程式檔和記錄模型的 header 檔而已,後者以陣列形式記錄了產生好的模型。
然後,我在網路上也找到了別人寫的程式,可以把訓練出來的 Tenworflow Lite 模型直接轉成 C++ 文字格式,不需要再很麻煩的去系統命令列用 xxd 轉換它。這麼一來,想把模型上傳到開發板的過程,突然就簡化很多了。
因此,下面我們就來看看你怎麼用 EloquentTinyML 讓你的人生變得更加好過。請注意筆者自己也是 Tensorflow 超級菜鳥,因此下面很多東西就沒法多加解釋囉。
訓練 Tensorflow 模型
當然,神經網路是比較複雜的玩意,第一步必定是從你的電腦上開始訓練。正如 TinyML 書上的第一個範例,下面的模型的原始資料只是用三角函數來產生、然後加些隨機噪訊而已。筆者做了點變化,目標值是 sin(x) 和 con(x) 相乘的結果,並稍微加大噪訊:
你的 Python 環境必須為 64 位元並有安裝 Tensorflow 2.0 以上版本,外加 NumPy 及 scikit-learn 等。留意 Tensorflow 只能使用特定的 NumPy 版本。
此外,TF Lite 的功能可能沒有標準 Tensorflow 完整,例如激勵函數只有 ReLU,ReLU6 和 softmax。
SAMPLES = 1000
ITERATION = 800
RANDOM_SEED = 1138
DISPLAY_SKIP = 50import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 關閉不必要的 loggingimport numpy as np
import tensorflow as tf
from tensorflow.keras import layers, Sequentialnp.random.seed(RANDOM_SEED)
tf.random.set_seed(RANDOM_SEED)# 列出可用 GPU
print(tf.config.list_physical_devices('GPU'))
# 列出可用 GPU (強迫無 GPU 電腦不使用 GPU - 雖然這功能將在新版移除)
print(tf.test.is_gpu_available())# 準備資料 (y = sin(x) + cos(x) 並加上隨機 "噪訊")
data = np.random.uniform(low=0, high=2*np.pi, size=SAMPLES)
np.random.shuffle(data)
target = np.sin(data) * np.cos(data) + 0.15 * np.random.randn(SAMPLES)# 切割資料集 (60% 訓練, 20% 驗證, 20% 測試)
from sklearn.model_selection import train_test_splitdata_train, data_test, target_train, target_test = train_test_split(
data, target, test_size=0.2)
data_train, data_valid, target_train, target_valid = train_test_split(
data_train, target_train, test_size=0.25)# 建立模型
model = Sequential()
model.add(layers.Dense(16, tf.nn.relu, input_shape=(1,)))
model.add(layers.Dense(16, tf.nn.relu))
model.add(layers.Dense(16, tf.nn.relu))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
model.summary()# 訓練模型並產生預測結果
history = model.fit(data_train, target_train,
epochs=ITERATION, batch_size=32,
validation_data=(data_valid, target_valid))
predictions = model.predict(data_test)
evaluate = model.evaluate(data_test, target_test)
下面是模型訓練出來後的視覺化結果,但程式碼比較複雜、跟本篇關係也不大,這邊就不貼了。你可以看到模型如何對應到資料,以及訓練過程中的損失值是如何降低的。

筆者還花了點時間安裝 nVIDIA GPU 套件,這樣就能用我的 GeForce GTX 1660 Ti 顯卡來幫忙訓練模型了!打開顯卡監控軟體,真的可以看到有在用捏。雖然當初買卡是為了玩《刺客教條:奧德賽》,而且就這個模型的訓練速度上,好像跟 CPU 沒啥差別就是。
這程式在筆者的筆電上(無支援的 GPU)也能跑,前提是必須加上 tf.test.is_gpu_available() 這行,否則就會因為試圖呼叫 CUDA 函式庫而產生錯誤。但是,現在又會跳出訊息說這功能即將廢除。這意味著你以後真的一定要用 GPU 來跑 Tensorflow 2,不然就只能乖乖用 1.x 版嗎?
把模型輸出為 C++
在你的 Python 環境安裝 TinyML gen 這個套件:
pip install tinymlgen然後在前面的程式後面加入這段:
# 把 Lite 模型輸出為 C++ 文字檔from tinymlgen import portc_code = port(model, optimize=True)with open('tf_lite_model.h', 'w') as f:
f.write(c_code)
你可能會看到以下錯誤訊息:Model.state_updates (from tensorflow.python.keras.engine.training) is deprecated and will be removed in a future version. 不過就我的情況,還是可以正常產生結果。據了解這將在新板 Tensorflow 修正。
就這麼簡單!tinymlgen.port() 會一手包辦將前面的 model 物件轉換為 Tensorflow Lite 模型的過程,並轉換為 C++ 格式文字傳回。optimize 參數設為 True 即為使用 quantization 最佳化。接著,只要把輸出的文字寫到檔案中就成了。
程式執行完後,會在電腦中儲存一個文字檔 tf_lite_model.h(檔名其實隨便你取,我們乾脆就把它命名成 header)。用文字檔開啟即可看到產生的內容:
#ifdef __has_attribute
#define HAVE_ATTRIBUTE(x) __has_attribute(x)
#else
#define HAVE_ATTRIBUTE(x) 0
#endif
#if HAVE_ATTRIBUTE(aligned) || (defined(__GNUC__) && !defined(__clang__))
#define DATA_ALIGN_ATTRIBUTE __attribute__((aligned(4)))
#else
#define DATA_ALIGN_ATTRIBUTE
#endifconst unsigned char model_data[] DATA_ALIGN_ATTRIBUTE = {0x24, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x12, 0x00, 0x1c, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00, 0x00, 0x00, 0x18, 0x00, 0x12, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0xd4, 0x10, 0x00, 0x00, 0xe8, 0x0a, 0x00, 0x00, 0xd0, 0x0a, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x04, 0x00, 0x08, 0x00, 0x08, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x13, 0x00, 0x00, 0x00, 0x6d, 0x69, 0x6e, 0x5f, 0x72, 0x75, 0x6e, 0x74, 0x69, 0x6d, 0x65, 0x5f, 0x76, 0x65, 0x72, 0x73, 0x69, 0x6f, 0x6e, 0x00, 0x0f, 0x00, 0x00, 0x00, 0x84, 0x0a, 0x00, 0x00, 0x70, 0x0a, 0x00, 0x00, 0x14, 0x0a, 0x00, 0x00, 0xb0, 0x09, 0x00, 0x00, 0x5c, 0x09, 0x00, 0x00, 0x48, 0x09, 0x00, 0x00, 0xf4,
...};
const int model_data_len = 4384;
在 Arduino IDE 安裝 EloquentTinyML
現在,在 Arduino IDE 的選單草稿碼點選匯入程式庫 → 管理程式庫,然後在程式庫管理員搜尋「EloquentTinyML」:
新增一個專案並儲存 — — 在此姑且命名為 TinyML.iso — — 然後把 tf_lite_model.h 丟進 Arduino 替前者建立的資料夾中。關掉 Arduino IDE 再重開 TinyML.iso,tf_lite_model.h 就會被一併匯入。之後你想更新模型時,可以重新取代一次檔案,或者用文字編輯器打開後貼上新內容。
撰寫 Arduino 草稿碼
接著就直接借用 EloquentTinyML 提供的範例,修改如下:
#include <EloquentTinyML.h>
#include "tf_lite_model.h" // TinyML 模型#define NUMBER_OF_INPUTS 1
#define NUMBER_OF_OUTPUTS 1
#define TENSOR_ARENA_SIZE 2 * 1024 // 模型使用記憶體大小Eloquent::TinyML::TfLite<NUMBER_OF_INPUTS, NUMBER_OF_OUTPUTS, TENSOR_ARENA_SIZE> ml;void setup() {
Serial.begin(9600);
ml.begin((unsigned char*) model_data); // 匯入模型
}void loop() {
// 隨機產生 x 和 y 當預測資料
float x = 3.14 * random(101) / 100;
float y = sin(x) * cos(x);
float input[1] = {x};
float predicted = ml.predict(input);Serial.print("Data: f(");
Serial.print(x);
Serial.print(") = ");
Serial.print(y);
Serial.print("\t predicted: ");
Serial.println(predicted);
delay(1000);
}
2022 年補:注意現在套件更新後,開頭必須引用以下標頭檔:
#include <eloquent_tinyml/tensorflow.h>此外建立模型物件 m1 的語法現在變成如下:
Eloquent::TinyML::TensorFlow::TensorFlow<NUMBER_OF_INPUTS, NUMBER_OF_OUTPUTS, TENSOR_ARENA_SIZE> ml;程式碼不長對吧?注意 model_data 是來自 tf_lite_model.h 內陣列的名稱。此外由於原資料是 const unsigned char,得轉換成 unsigned char 陣列才能給 EloquentTinyML 使用。
另外,TinyML 一書說 TENSOR_ARENA_SIZE 大小要自己試驗,設到模型剛好能正常運作的最小數字,並以 1024 為級距調整。設為 1 * 1024 上傳後模型會不停吐出亂碼,所以正確數字就是 2 * 1024 啦。
就我目前所知,如果模型的節點太多(包括輸入 features 太多),就可能佔據太多記憶體而無法在板子上順利運作,不管你分配多少 tensor arena size 都一樣。所以設計模型時請想辦法精簡它吧…
上傳至 ESP32 開發板
現在就來上傳程式到 ESP32 上吧:
如果你還沒用過 ESP32,你得在檔案 → 偏好設定的開發板管理員網址加入 https://raw.githubusercontent.com/espressif/arduino-esp32/gh-pages/package_esp32_index.json,然後到工具 → 開發板 → 開發板管理員安裝「esp32」。你也可能得安裝 CP2102 或 CH340G USB 晶片驅動程式。
上傳程式前,請選取對應規格的開發板(不確定就選 DOIT ESP32 DEVKIT V1 或 NodeMCU-32S),以及板子所在的序列埠。有些 ESP32 在上傳時需要按住 reset 一段時間才能使它正確進入燒錄模式。

草稿碼使用了 412022 bytes (31%) 的程式儲存空間。上限為 1310720 bytes。
全域變數使用了 25628 bytes (7%) 的動態記憶體,剩餘 302052 bytes 給區域變數。上限為 327680 bytes 。
esptool.py v2.6
Serial port COM21
Connecting........_____.
Chip is ESP32D0WDQ6 (revision 1)
Features: WiFi, BT, Dual Core, 160MHz, VRef calibration in efuse, Coding Scheme None
MAC: 84:0d:8e:0c:16:54
Uploading stub...
Running stub...
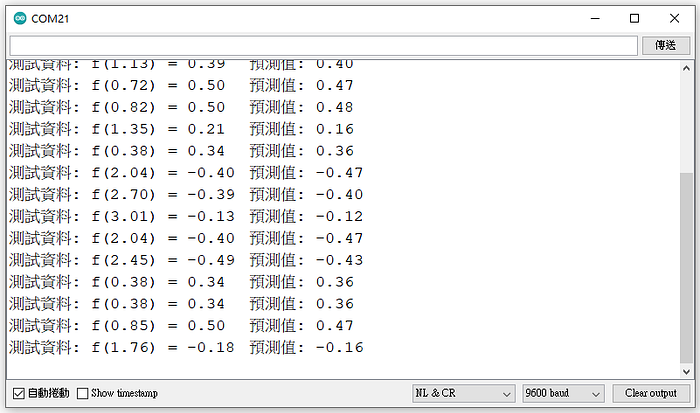
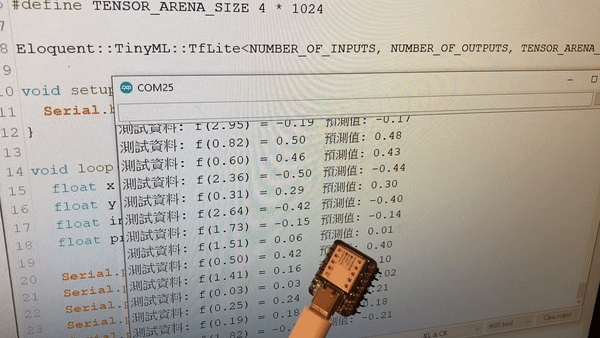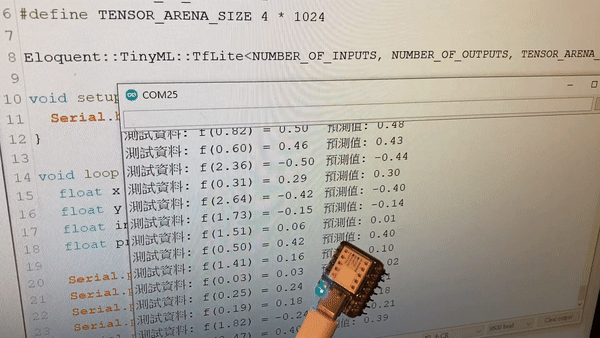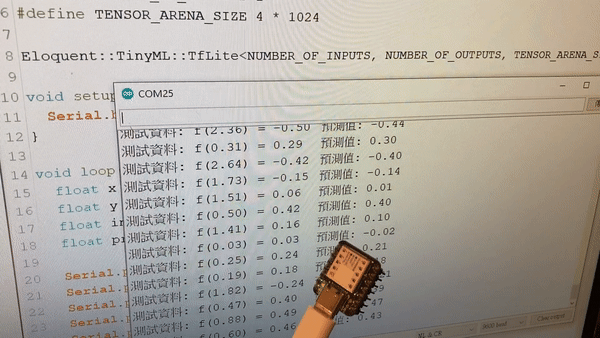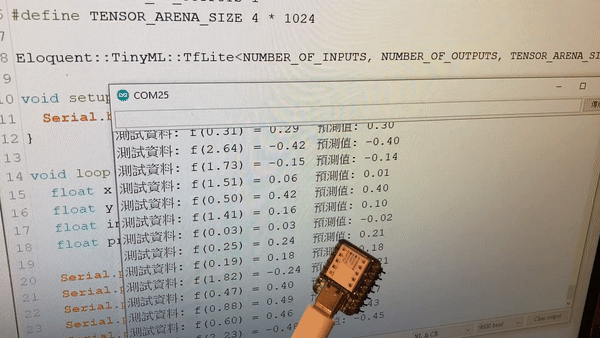
Stub running...打開工具 → 序列埠監控視窗,就能看到 ESP32 預測模擬資料的結果:
至於TinyML 這本書中有列出的 Arduino Nano 33 BLE(你得在開發板管理員中安裝「Arduino nRF528x Boards」)自然也可上傳此草稿碼。筆者有買一塊 BLE Sense,也就是標準 BLE 外加一堆內建感測器的版本,可以用來搭配 TinyML 做顏色、手勢跟聲音辨識,感覺就是串通好的行銷計畫XD
不過,前陣子 ESP32 也正式獲得 Tensorflow Lite 支援了,這使得一些像是 ESP32-CAM 這種附帶有攝影機的板子重新獲得注意。

其實…
筆者當然也有嘗試把這隻程式燒錄到其他記憶體或許夠大的開發板上。但是,Arduino Nano 33 IoT(SAMD21)、Adafruit Playground Express(SADM21)和 Bluepill(STM32F103)都會編譯錯誤。Adafruit Metro M4(SAMD51)則可以。
意想不到的是,還有兩塊板子竟然也編譯成功,上傳後程式也能正常運作…它們分別是 ESP8266 及 Seeeduino Xiao(也是 SAMD21)。
草稿碼使用了 394700 bytes (37%) 的程式儲存空間。上限為 1044464 bytes。
全域變數使用了 51500 bytes (62%) 的動態記憶體,剩餘 30420 bytes 給區域變數。上限為 81920 bytes 。
esptool.py v2.8
Serial port COM21
Connecting....
Chip is ESP8266EX
Features: WiFi
Crystal is 26MHz
MAC: 2c:f4:32:2d:69:11
Uploading stub...
Running stub...
Stub running...當然,這兒用的只是個很簡單的模型。但是,這就意味著你能在更便宜的 ESP8266 上運用簡單的神經網路,甚至能跟 ESP32 一樣結合 IoT 打造出 AIoT 應用。
2022 年補:重新測試發現 ESP8266 已經無法正常編譯上傳了,但 Xiao 仍然可以。Raspberry Pi Pico 與 Arduino Nano RP2040 Connect也可正常上傳(Pico 燒錄前要先按住 BOOT 再接線)。
下面則是燒錄到 XIAO 的訊息:
草稿碼使用了 145364 bytes (55%) 的程式儲存空間。上限為 262144 bytes。
Device : ATSAMD21x18
Version : v1.1 [Arduino:XYZ] Nov 27 2019 16:35:59
Address : 0x0
Pages : 4096
Page Size : 64 bytes
Total Size : 256KB
Planes : 1
Lock Regions : 16
Locked : none
Security : false
BOD : true
BOR : true
Write 145996 bytes to flash (2282 pages)
[==============================] 100% (2282/2282 pages)
Done in 27.641 seconds
Verify 145996 bytes of flash
[==============================] 100% (2282/2282 pages)
Verify successful
Done in 4.361 seconds說真的,筆者也不知道為何其他 SAMD21 就會編譯錯誤。Seeeduino Xiao(我發誓真的沒收過廣告費!XD)是個跟十元硬幣一樣大的超小型開發板,這表示你能更輕易地拿它打造穿戴式裝置原型。說不定只要接個血氧濃度計感測器或加速計,就能有很實務的用處了。
結語
對筆者自己而言,接下來要研究的課題,自然是如何將 TinyML 應用在真實場合了。這包括如何設計一個程式來從板子收集資訊並設定分類,給電腦讀取後做訓練並佈署模型。
當然,機器學習是個正如火如荼發展的領域,隨時都可能有新技術冒出來。約一周前,一間美國公司 Qeexo 宣布他們的 AutoML(automated machine learning)工具已經能應用在 Cortex M0+ 和 M4 裝置上 — — 包括 Arduino Nano 33 IoT — — 而且提供了十幾種模型跟視覺化的操作介面。雖然這應該是要收費的服務,但這意味著自動化的 TinyML 說不定將能大大降低非行內人士運用機器學習的門檻。畢竟,不是每個人都會對數學跟 coding 有興趣吧。
